In the last blog I discussed transactions. In this blog I want to highlight the scalability and high availability features available in Neo4j.
RDBMS’s are designed to run on big boxes. Scaling is done virtually by throwing more hardware at the server. This is in complete contract to NoSQL databases which are designed to be distributed systems that scale horizontally using lots of smaller commodity hardware. Neo4j utilizes the following scalability and high availability features.
Neo4j supports a master to multiple replica architecture with no Sharding. It prefers to keep the data local but allow read scaling by all writes going to the masters and then fanning out to the replicas. This gets you affectively unlimited scaling however; in practise the number of servers required is in the 10’s.
Causal Clustering
A Neo4j Causal cluster is one that follows the Causal Consistency model for data availability. That means, if I don’t have the data I know someone who does.
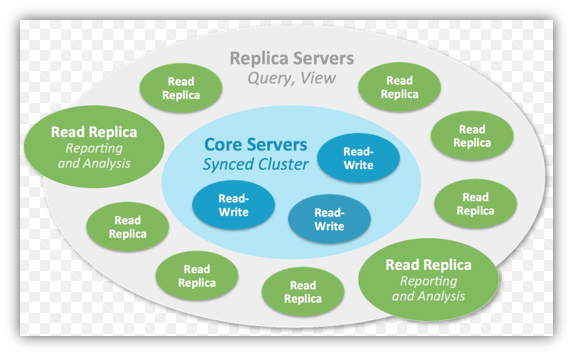
There are a number of read/write servers, at least three typically (See HA below). This is what we call a node majority model where as long as more servers are up than down, the database is deemed consistent and available. Once the data is written to the masters and fully durable, it is then sent to the replicas asynchronously. The master servers (Core Servers in the diagram) is where your data is safeguarded and the replicas is where the read scaling come in.
Highly Available (HA) Clustering
A highly available cluster uses the same architecture as a causal cluster, the difference comes when dealing with a hardware or network failure. HA systems require a quorum. This is a way of determining who is the current master owner of the data. Image a network failure, all servers are still running however; we cannot have users writing to one server and other users writing to another server. This is why we need an odd number of masters to determine a quorum.
When a failure occurs if required the process can promote a replica as a master and also deal with data synchronization when the failure is resolved.

