In the last blog I discussed the various types of data loading options Neo4j offers. In this blog I will take the Northwind database and convert it to a Neo4j graph database model.
Contents
- Converting an RDBMS Model
- Data Types
- Converting Tables that do not participate in Joins
- Converting One to One/One to Many Joins
- Converting a Self-Join
- Converting a Many to Many Join (No Relationship Properties)
- Converting two more One to Many Joins
- Converting a Many to Many Join (With Relationship Properties)
- Finished Model
Converting an RDBMS Model
I like the Northwind database for simple tutorials. I have used it for years because it contains one to one, one to many and many to many relationships. It turns out that Neo4j examples also like it and you will find lots of examples using this database. Rather than shy away and use another example database like AdventureWorks, I am still going to use Northwind but convert it from my perspective rather than rehash what is already written.
Data Types
When moving to Neo4j you need to think about the data types. For example; Neo4j does not have a datetime type and therefore you need to make a decision on how you will represent a date and time in Neo4j. Some designs store the number of milliseconds since a given date. Neo4j does have a timestamp() function that does this. Some store the date as YYYYMMDD. There are many ways and this value can be reformatted during the extract and transform phase when loading the data. Also by default a value will be stored as a string in Neo4j so you will need to use one of the functions toInteger(), toFloat() or toBoolean() to get the correct representation.
Converting Tables that do not participate in Joins
Tables that do not participate in joins are easy candidates for converting. Each row becomes a node and each column in the row is added as a property. The table name is added as a Label to each node. Northwind does not have any tables that do not participate in any joins.
Converting One to One/One to Many Joins
Denormalization is a natural design decision in NoSQL databases unlike RDBMS’s which only perform it if there are performance or scalability issues. Neo4j kind of sits on the fence of RDBMS/NoSQL and since it thrives on data relations, actually retaining a fully normalized model is not a bad design decision. It always boils down to the queries you will be performing. Let’s use the Products table as our example here. Always profile your data to check if it is a one to one or a one to many. In our case the Categories table has a one to many mapping. Do we retain categories as separate nodes or do we denormalize the data and add it into each Product node. If you add it to the Product node it is likely you will need to index it. A reason for not adding it would be if the Categories table has lots of columns. There would be a lot of duplication for maybe no benefit.
For this tutorial I am going to include the CategoryName into each Product node and exclude the other three columns. I will then index this column.
The Suppliers table also has a one to many mapping to the Products table however; it has allot of useful columns so we will leave it as it is and build individual Supplier nodes. Before we do that we need to look at the primary keys for Products and Suppliers. We have a ProductID and a SupplierID. Do we include these columns in our Neo4j model? If the key is a Natural Key then the answer is yes every time. If we use an alternate field that is also unique it is likely you will create a unique constraint. Using our Suppliers example; we could use CompanyName however; it’s a large string and this would create a large index. For this tutorial I will keep both integer keys. Another question is “do we include foreign keys”? Not in the Neo4j model however; keep them in the CSV file and it can be used to create the SUPPLIES relationship.
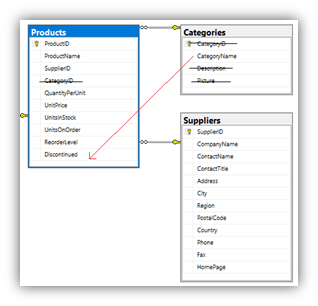
So looking at the RDBMS schema above, we will convert it to the following Neo4j schema.

We will create two CSV files using the following SQL.
SELECT P.*, C.CategoryName FROM Products AS P JOIN Categories AS C ON (p.CategoryID = c.CategoryID) SELECT * FROM Suppliers
Quick note on the CSV files. We will be using LOAD CSV:
- Save them as UTF-8 (No BOM)
- Always include a header. Remove spaces between the commas.
- Watch out for commas stored in description or note type fields.
- If the CSV contains NULL for a field, if you replace it with a blank field so you get two commas side by side, LOAD CSV will not add it as a property. Anything else will be added as a property into Neo4j.
- Comment our or change the server setting dbms.directories.import if you need to specify a different local folder.
Here are the LOAD CSV commands to create the Product and Supplier nodes and the SUPPLIES relationship.
-- Product LOAD CSV WITH HEADERS FROM "file:///products.csv" AS data MERGE (n:Product {ProductID: data.ProductID}) ON CREATE SET n.Product = data.ProductName, n.Category = data.CategoryName, n.QuantityPerUnit = data.QuantityPerUnit, n.UnitPrice = toFloat(data.UnitPrice), n.UnitsInStock = toInteger(data.UnitsInStock), n.UnitsOnOrder = toInteger(data.UnitsOnOrder), n.ReorderLevel = toInteger(data.ReorderLevel), n.Discontinued = (data.Discontinued "0") CREATE CONSTRAINT ON (n:Product) ASSERT n.ProductID IS UNIQUE -- Supplier LOAD CSV WITH HEADERS FROM "file:///suppliers.csv" AS data MERGE (n:Supplier {SupplierID: data.SupplierID}) ON CREATE SET n.Company = data.CompanyName, n.Contact = data.ContactName, n.ContactTitle = data.ContactTitle, n.Address = data.Address, n.City = data.City, n.Region = data.Region, n.PostalCode = data.PostalCode, n.Country = data.Country, n.Phone = data.Phone, n.Fax = data.Fax, n.HomePage = data.HomePage CREATE CONSTRAINT ON (n:Supplier) ASSERT n.SupplierID IS UNIQUE -- Product to Supplier Relationship LOAD CSV WITH HEADERS FROM "file:///products.csv" AS data MATCH (p:Product),(s:Supplier) WHERE p.ProductID = data.ProductID AND s.SupplierID = data.SupplierID CREATE (s)-[:SUPPLIES]->(p)
Notice:
- We did not have to include every field in our node
- We also took the opportunity to rename the properties.
- We included the to… functions to ensure the correct data type was used.
- The discontinued property in the CSV was not a string so I had to use the expression (data.Discontinued “0”) in order to create a Boolean type. I could not use toBoolean() because it expects a value of “true” or “false”, not 1 or 1.
After the data is loaded in we should see something like the following:
MATCH (n) -[]- (o) WHERE n.Company = ‘New Orleans Cajun Delights’ RETURN *
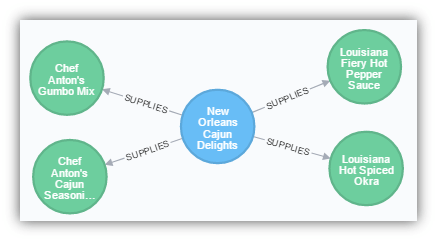
Converting a Self-Join
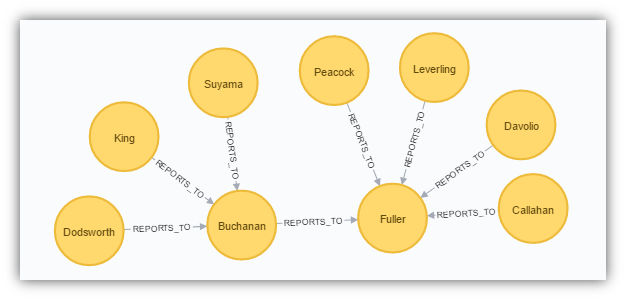
The employees table has a self-join which creates a hierarchy of employee to manager. The table uses the ReportsTo column to point to the EmployeeID of its manager. In order to model I will use a slightly different approach to what we did in the previous example. Instead of including the ReportsTo column in the CSV, I will generate a second CSV which just the relationships. Also the Employee table includes three dates and I will be converting the dates to YYYYMMDD in the CSV file.

So looking at the RDBMS schema above, we will convert it to the following Neo4j schema.

We will create two CSV files using the following SQL.
SELECT EmployeeID, LastName, FirstName, Title, TitleOfCourtesy, CONVERT(VARCHAR,BirthDate,112) AS [BirthDate],
CONVERT(VARCHAR,HireDate,112) AS [HireDate], Address, City, Region, PostalCode, Country, Extension, Notes
FROM Employees
SELECT E2.EmployeeID, E1.EmployeeID AS [ReportsTo]
FROM Employees AS E1
JOIN Employees AS E2 ON (E1.EmployeeID = E2.ReportsTo)
Here are the LOAD CSV commands to create the Employee nodes and the REPORTS_TO relationship.
-- Employee LOAD CSV WITH HEADERS FROM "file:///employees.csv" AS data MERGE (n:Employee {EmployeeID: data.EmployeeID}) ON CREATE SET n.LastName = data.LastName, n.FirstName = data.FirstName, n.Title = data.Title, n.TitleOfCourtesy = data.TitleOfCourtesy, n.BirthDate = data.BirthDate, n.HireDate = data.HireDate, n.Address = data.Address, n.City = data.City, n.Region = data.Region, n.PostalCode = data.PostalCode, n.Country = data.Country, n.HomePhone = data.HomePhone, n.Extension = data.Extension, n.Notes = data.Notes CREATE CONSTRAINT ON (n:Employee) ASSERT n.EmployeeID IS UNIQUE -- Employee Relationship to Manager LOAD CSV WITH HEADERS FROM "file:///Employees_ReportsTo.csv" AS data MATCH (n:Employee {EmployeeID: data.EmployeeID}), (o:Employee {EmployeeID: data.ReportsTo}) MERGE (n)-[:REPORTS_TO]->(o)
After the data is loaded in we should see something like the following:
MATCH (n:Employee) RETURN n
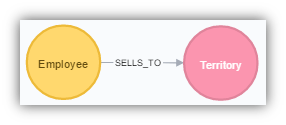
Converting a Many to Many Join (No Relationship Properties)
When describing a many to many join in an RDBMS it is normal to create an intermediate table which has a one to many relationship to each of the other two tables. This is not a requirement for Neo4j. The only two columns we are interested in are TerritoryDescription and RegionDescription. We can create a Territory node with these two properties.
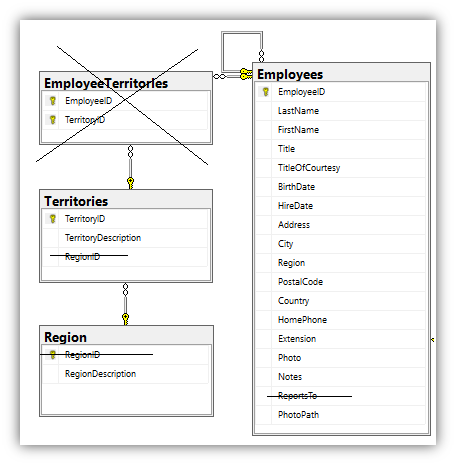
So looking at the RDBMS schema above, we will convert it to the following Neo4j schema.
We will create two CSV files using the following SQL.
SELECT T.TerritoryID, T.TerritoryDescription, R.RegionDescription FROM Territories AS T JOIN Region AS R ON (R.RegionID = T.RegionID) SELECT * FROM EmployeeTerritories
Here are the LOAD CSV commands to create the Territory nodes and the SELLS_TO relationship.
-- Territories LOAD CSV WITH HEADERS FROM "file:///Territories.csv" AS data MERGE (n:Territory {TerritoryID: data.TerritoryID}) ON CREATE SET n.Territory = data.TerritoryDescription, n.Region = data.RegionDescription CREATE CONSTRAINT ON (n:Territory) ASSERT n.TerritoryID IS UNIQUE -- Employee to Territory Relationship LOAD CSV WITH HEADERS FROM "file:///Employees_Territories.csv" AS data MATCH (n:Employee {EmployeeID: data.EmployeeID}), (o:Territory {TerritoryID: data.TerritoryID}) MERGE (n)-[:SELLS_TO]->(o)
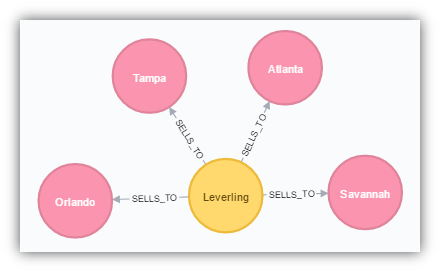
After the data is loaded in we should see something like the following:
MATCH (n:Employee)-[SELLS_TO]->(o:Territory) RETURN *
Converting two more One to Many Joins
The Customers table has a one to many relationship with the Orders table. As we did with the previous examples; we will remove the foreign key and create the relationship from a CSV file. Orders also have a one to many mapping between Orders and Shippers. Since Shippers just has two columns, we will pull these into the Orders table.
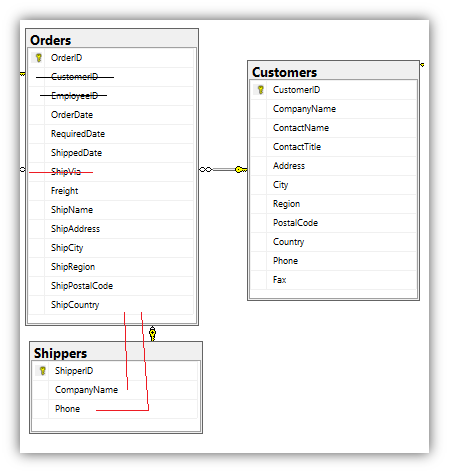
So looking at the RDBMS schema above, we will convert it to the following Neo4j schema.
We will create two CSV files using the following SQL.
SELECT *
FROM Customers
SELECT O.OrderID, O.CustomerID, O.EmployeeID, CONVERT(VARCHAR,O.OrderDate,112) AS [OrderDate],
CONVERT(VARCHAR,O.RequiredDate,112) AS [RequiredDate], CONVERT(VARCHAR,O.ShippedDate,112) AS [ShippedDate],
S.CompanyName AS [ShippingCompany], S.Phone AS [ShippingPhone], O.ShipName, O.ShipAddress, O.ShipCity,
O.ShipRegion, O.ShipPostalCode, O.ShipCountry
FROM Orders AS O
JOIN Shippers AS S ON (S.ShipperID = O.ShipVia)
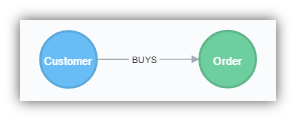
Here are the LOAD CSV commands to create the Customer and Order nodes and the BUYS relationship.
-- Customer LOAD CSV WITH HEADERS FROM "file:///customers.csv" AS data MERGE (n:Customer {CustomerID: data.CustomerID}) ON CREATE SET n.CustomerID = data.CustomerID, n.Company = data.CompanyName, n.Contact = data.ContactName, n.ContactTitle = data.ContactTitle, n.Address = data.Address, n.City = data.City, n.Region = data.Region, n.PostalCode = data.PostalCode, n.Country = data.Country, n.Phone = data.Phone, n.Fax = data.Fax CREATE CONSTRAINT ON (n:Customer) ASSERT n.CustomerID IS UNIQUE -- Orders LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS data MERGE (n:Order {OrderID: data.OrderID}) ON CREATE SET n.OrderDate = data.OrderDate, n.RequiredDate = data.RequiredDate, n.ShippedDate = data.ShippedDate, n.ShippingCompany = data.ShippingCompany, n.ShippingPhone = data.ShippingPhone, n.ShipName = data.ShipName, n.ShipAddress = data.ShipAddress, n.ShipCity = data.ShipCity, n.ShipRegion = data.ShipRegion, n.ShipPostalCode = data.ShipPostalCode, n.ShipCountry = data.ShipCountry LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS data MATCH (o:Order {OrderID: data.OrderID}), (c:Customer {CustomerID: data.CustomerID}) MERGE (c)-[:BUYS]->(o) CREATE CONSTRAINT ON (n:Order) ASSERT n.OrderID IS UNIQUE
After the data is loaded in we should see something like the following:
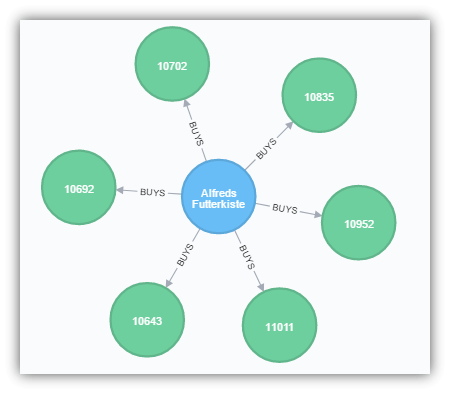
MATCH (c:Customer)-[:BUYS]->(o:Order) WHERE c.CustomerID = ‘ALFKI’ RETURN *
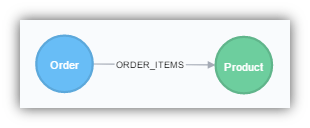
Converting a Many to Many Join (With Relationship Properties)
The last change we need to perform is when we have a many to many relationship and the intermediate table has additional columns of data. The Order Details table is a join between Products and Orders. The table also includes three numerical properties. An order includes one or more products and for each product in the order, we need to know the quantity, price and any discounts. We already have Product and Order nodes created previously. All we now need is to create an ORDER_ITEM relationship which includes the three properties described.

So looking at the RDBMS schema above, we will convert it to the following Neo4j schema.
I will create one CSV files using the following SQL.
SELECT * FROM [Order Details]
Here are the LOAD CSV commands to create the ORDER_ITEM relationship.
LOAD CSV WITH HEADERS FROM "file:///orderdetails.csv" AS data
MATCH (o:Order {OrderID: data.OrderID}), (p:Product {ProductID: data.ProductID})
MERGE (o)-[:ORDER_ITEM {UnitPrice: toFloat(data.UnitPrice), Quantity: toInteger(data.Quantity), Discount: toInteger(data.Discount)}]->(p)
After the data is loaded in we should see something like the following:
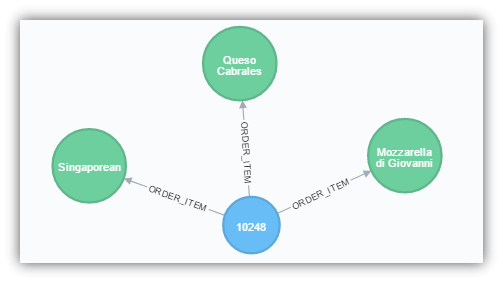
MATCH (o:Order)-[:ORDER_ITEM]->(p:Product) WHERE o.OrderID = ‘10248’ RETURN *
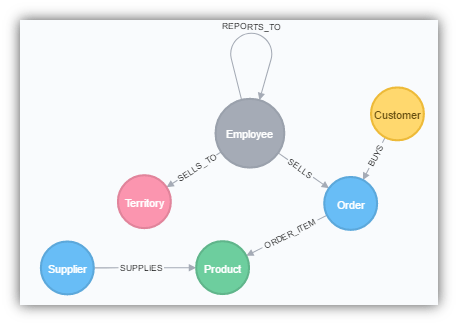
Finished Model
Here is the before and after. We have gone from 11 tables to 6 nodes.

In the next blog I will show some example Cypher queries.
