In the previous blog I highlighted the scalability and high availability features available in Redis. In this blog I will show how a demo application uses Redis to cache searches sent to Twitter. The code can be found on Github here.
Demo Application
In this last post I thought I would show one of the uses of Redis. When Redis is configured with no durability, it becomes a super-fast cache for online queries to sites such as Twitter, etc.
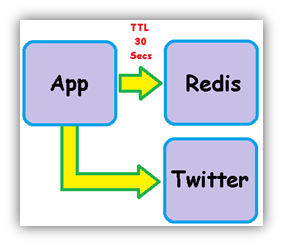
The app does a twitter search using a passed in search string. The results are stored in Redis using the search string as the key. The key has a Time to Live (TTL) of 30 seconds. If an identical search is done within 30 seconds, the data is pulled from Redis by the client. After 30 seconds the key is automatically deleted and the app redirects the request to Twitter the next time the same search is requested. Here is an example of the output returned. It is run using python main.py #python to return the latest 20 tweets that mentioned #python.
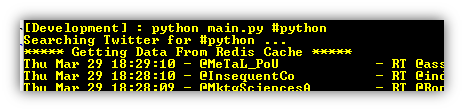
Here is the output. Notice the text prefixed with *****. It indicates the search request was sent to twitter.

Here is a request sent a few seconds after and now the message indicates the results came from Redis.
If we use the TTL command for the key #python, we see that it has 16 seconds remaining until it expires.

Code Discussion
The code uses the twitter library from https://pypi.python.org/pypi/twitter. The link has some examples on how to use the API however; for this demonstration I only used the search.tweets command. The command returns a very extensive dictionary called TwitterDictResponse which I pulled out the Statuses list and discarded everything else.
Before I stored the Statuses list in Redis I first converted it to JSON. I did this because there is no one to one mapping between Redis types and Python types. In fact in Redis the data is stored as byte arrays and loses the source type metadata. By storing it as JSON it meant that when I retrieved it, I could use the JSON library to deserialize it back to a list. I used the Redis command SETEX which stores the results in the string value type and allows me to set the TTL which is handled automatically by Redis. The search string is used as the key.
import twitter
import redis
import settings
import json
import sys
# Redis Time to Live = 30 Seconds
REDISTTL = 30
TWEET_COUNT = 20
t = twitter.Twitter(auth = twitter.OAuth(settings.twitterSettings["token"], settings.twitterSettings["token_secret"], settings.twitterSettings["consumer_key"], settings.twitterSettings["consumer_secret"]))
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
def CheckRedisCache(query):
_res = r.get(query)
if (_res is None):
return None
print("***** Getting Data From Redis Cache *****")
# Deserialize the JSON back into a Python list
return json.loads(_res.decode('utf-8'))
def FetchFromTwitter(query):
print("***** Getting Data From Twitter *****")
_results = t.search.tweets(q = query, count = TWEET_COUNT)
_redisValue = {}
_redisValue = _results["statuses"]
# Store the Python list as JSON in Redis with expiry
r.setex(query, json.dumps(_redisValue), REDISTTL)
return _results["statuses"]
if __name__ == "__main__":
if (len(sys.argv) < 2):
print("Usage: main.py ")
sys.exit()
_search = sys.argv[1]
print("Searching Twitter for", _search, "...")
_results = CheckRedisCache(_search)
if (_results is None):
_results = FetchFromTwitter(_search)
for _res in _results:
print("{:19s} - @{:20s} - {:140s}".format(_res["created_at"][0:19], _res["user"]["screen_name"][0:20], _res["text"].replace("\n"," ")))
Conclusion
I hope you found this blog series useful and it encourages you to use key value store databases in your designs.
