In the last blog I discussed NULLs and data denormalization. The code can be found on Github here. In this blog I will show how we can apply filters to our data.
Filtering data is limiting the data returned based on conditions. In SQL this is accomplished by a WHERE clause. Doing filtering on the server reduces the amount of data that has to be sent across a network to the client.
The following common queries will be shown
- Filtering on a keys value
- Filtering on multiple keys
- Filtering on a range
Filtering on a Keys Value
Using our customer data let’s say we want to return all customers who are based in France. This is a predicate of Country = “France”. In order to accomplish this on the server we need to create a key for each country and add the customer IDs to the appropriate key.
I have created a set called customer-country:<COUNTRY>. The reason I use a set and not a list will be explained later on. Look at the code in 07_Create_Customers_Country_Key.py which is used to generate the keys.
import settings
import redis
import csv
import sys
import os
def ProcessCSVFile(r, csvin):
with open(csvin, 'rt', encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quoting=csv.QUOTE_NONE, )
# Ignore Row Header
next(spamreader)
for row in spamreader:
ProcessCustomerRow(r, row)
def ProcessCustomerRow(r, row):
# CSV Header
# ID,Company,Contact,ContactTitle,Address,City,Region,PostalCode,Country,Phone,Fax
_key = "customer-country:" + row[8]
_id = row[0]
r.sadd(_key, _id)
if __name__ == "__main__":
print("Reading Customers...")
_csvPath = os.path.dirname(os.path.dirname(__file__))
_customersCSV = os.path.join(_csvPath, "CSVs", "customers.csv")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
ProcessCSVFile(r, _customersCSV)
print("Reading Customers Completed")
When we have finished we will have keys like the following for example:
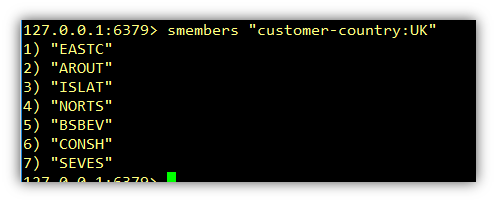
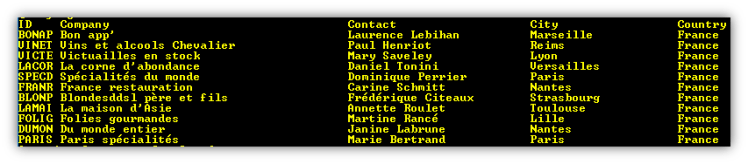
Using the smembers command we can get all the customer IDs of those who are based in France. Then get the fields of each customer using hgetall. See code file 08_Query_Customers_From_France.py.
import settings
import redis
def ProcessCustomer(key):
# Get all keys and values from hash
_cust = r.hmget("customer:" + key.decode('utf-8'), "ID", "Company", "Contact", "City", "Country")
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8'),
_cust[3].decode('utf-8'),
_cust[4].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Customers...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Get all the Customer Keys. This does a SCAN under the covers
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format("ID","Company","Contact","City","Country"))
for key in r.smembers("customer-country:France"):
ProcessCustomer(key)
print("Querying Customers Completed")
Here is the output.
Filtering on Multiple Keys
Continuing on from the previous query. Say we also want to return all customers who are based in France and the contact title of Owner. We now need another set for contact title called customer-contacttitle:<contacttitle>. See code file 09_Create_Customers_Contact_Title_Key.py. Note: The contact titles have spaces in the name so these were replaced with periods.
import settings
import redis
import csv
import sys
import os
def ProcessCSVFile(r, csvin):
with open(csvin, 'rt', encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quoting=csv.QUOTE_NONE, )
# Ignore Row Header
next(spamreader)
for row in spamreader:
ProcessCustomerRow(r, row)
def ProcessCustomerRow(r, row):
# CSV Header
# ID,Company,Contact,ContactTitle,Address,City,Region,PostalCode,Country,Phone,Fax
_key = "customer-contacttitle:" + row[3].replace(" ",".")
_id = row[0]
r.sadd(_key, _id)
if __name__ == "__main__":
print("Reading Customers...")
_csvPath = os.path.dirname(os.path.dirname(__file__))
_customersCSV = os.path.join(_csvPath, "CSVs", "customers.csv")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
ProcessCSVFile(r, _customersCSV)
print("Reading Customers Completed")
Let’s look at the members of each set.
|
|
|
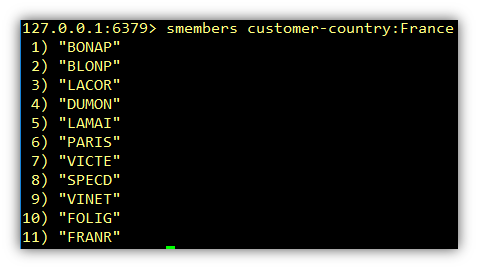
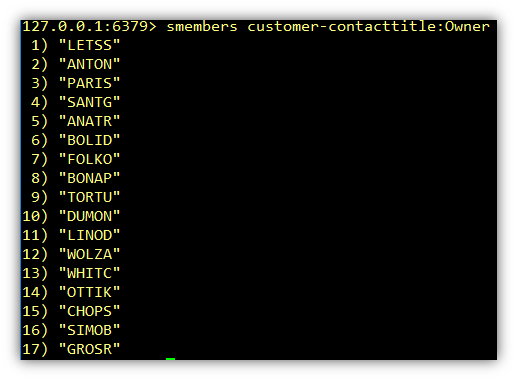
In order to get the correct result we need to return just the IDs that appear in each set. Looking above we can see that BONAP, DUMON and PARIS are the only ids that appear in both. Here is now the reason why I chose to store these in sets and not in a list. It is because in set theory we have unions, set differences and intersections to compare sets. ANDing sets is called an Intersection and ORing sets is called a Union. Set Differences are used to return all items from the first set that are not in any other set. Since we need to AND the two sets, in Redis we can use the SINTER command.

Using the sinter command we can get all the customer IDs of those who are based in France and the contact title is Owner. Then get the fields of each customer using hgetall. See code file 10_Query_Customers_From_France_And_Owner.py.
import settings
import redis
def ProcessCustomer(key):
# Get all keys and values from hash
_cust = r.hmget("customer:" + key.decode('utf-8'), "ID", "Company", "Contact", "ContactTitle", "City", "Country")
print("{:5s} {:40s} {:40s} {:25s} {:20s} {:20s}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8'),
_cust[3].decode('utf-8'),
_cust[4].decode('utf-8'),
_cust[5].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Customers...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Get all the Customer Keys. This does a SCAN under the covers
print("{:5s} {:40s} {:40s} {:25s} {:20s} {:20s}".format("ID","Company","Contact","Contact_Title","City","Country"))
for key in r.sinter("customer-country:France","customer-contacttitle:Owner"):
ProcessCustomer(key)
print("Querying Customers Completed")
Here is the output.

Filtering On a Range
Another type of query is a numerical range query. In SQL it would be something like WHERE Age BETWEEN 10 AND 20. In order to achieve the same thing in Redis we need to use a Sorted Set. For our example; I have imported Northwind products using keys product:. See code file 11_Import_Products.py. The code follows the same principal as the customer data. I then created a Sorted Set called product-all:unitprice which has a value for each product id and the unitprice as the score. Each value was added using the ZADD command. See code file 12_Create_Products_UnitPrice_Key.py.
import settings
import redis
import csv
import sys
import os
def ProcessCSVFile(r, csvin):
with open(csvin, 'rt', encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quoting=csv.QUOTE_NONE, )
# Ignore Row Header
next(spamreader)
for row in spamreader:
ProcessCustomerRow(r, row)
def ProcessCustomerRow(r, row):
# CSV Header
# ID,Product,Category,QuantityPerUnit,UnitPrice,UnitsInStock,UnitsOnOrder,ReorderLevel,Discontinued
_key = "product-all:unitprice"
_id = row[0]
_unitPrice = row[4]
r.zadd(_key, _id, _unitPrice)
if __name__ == "__main__":
print("Reading Products...")
_csvPath = os.path.dirname(os.path.dirname(__file__))
_customersCSV = os.path.join(_csvPath, "CSVs", "products.csv")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
ProcessCSVFile(r, _customersCSV)
print("Reading Products Completed")
For example; here is the unit price for product id 64.


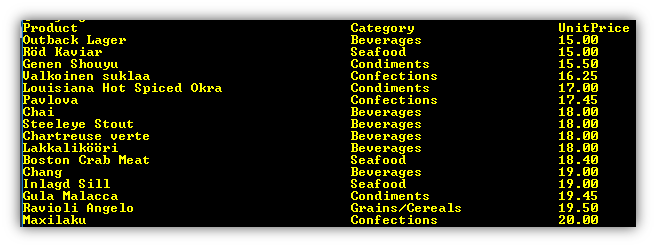
Using the command zrangebyscore, we can fetch all the product ids where the value is between 15.00 and 20.00 dollars. Then get the fields of each product using hgetall. See code file 13_Query_Products_By_UnitPrice.py.
import settings
import redis
# ID,Product,Category,QuantityPerUnit,UnitPrice,UnitsInStock,UnitsOnOrder,ReorderLevel,Discontinued
def ProcessCustomer(key):
# Get all keys and values from hash
_cust = r.hmget("product:" + key.decode('utf-8'), "Product", "Category", "UnitPrice")
print("{:40s} {:25s} {:}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Products...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
_key = "product-all:unitprice"
# Get all the Customer Keys. This does a SCAN under the covers
print("{:40s} {:25s} {:25s}".format("Product","Category","UnitPrice"))
for key in r.zrangebyscore(_key, 15.00, 20.00):
ProcessCustomer(key)
print("Querying Products Completed")
Here is the output.
Conclusion
By now it should be clear that Redis does not have a rich query language like SQL. It does implement the language LUA on the server side however; I have not looked at this. We have seen how aggregations like COUNT need to be pre-calculated and stored separately. Fields used for sorting and filtering need to have lists and sets defined for them. Using the same techniques in this blog it should now be clear on how we would implement one to many and many to many joins.
That concludes this blog. In the next blog I want to discuss transactions.
