In the last blog I introduced the Redis data types. In this blog I will cover how we create our first data model and some queries. The code can be found on Github here.
Relational Background
A lot of people who come to a NoSQL database come from a relational database background and it’s no surprise they begin looking at a NoSQL database with a relational mind-set. They think queries using SQL and data as tabular results. There is nothing wrong with this as long as you understand that this will not take you too far and knowing that you need to look at it differently will then allow you to get the best out of it. For some of you this will make Redis look fairly primitive since you have had the luxury of powerful data querying however; remember that NoSQL does not replace relational databases. It provides solutions to known problems where relational databases are not the best fit.
Redis Loves Keys, does not care about Values
That’s quite a bold statement. The first very important thing to realise is that keys are what we query and not values. This may seem strange when we think, “well how do I filter on someone’s name”. This is where we need to understand how data is modelled in Redis. So this brings us to the next important thing. You need to design your model based on how you will query it. For example; you want to keep a count of the number of customers. In a relational model we would just do a SELECT COUNT(*)…. We do not have that in Redis. In Redis You create a key called customer:count with a integer value for example; and every time you add a customer you increment it and when you delete a customer, you decrement it. To query the count is just a simple case of calling GET customer:count.
Key Naming Convention
A key can be called anything and can be MB’s in size but practically it should reflect succinctly what the data is. Most typically you will see keys with a : (Colon), . (Period), _ (Underscore), or – (Hyphen) in the name in order to aid scanning with wildcards.
For example. We have a Customer object and so a key that begins with customer is a good start. Remember, key names need to be unique. So next we need to look at what properties makes a customer unique. If its customer ID then we can create customer:1, customer:2, etc. What if it was firstname and lastname that made it unique? We could create customer:fred:flintstone, customer:barney:rubble, etc. If a value had a space in the name then we use a period or hyphen. E.g. Customer:farah:fawcett.majors.
Remember above I mentioned you need to understand what queries you need to perform in order to understand the model. If we also had customer:count and we needed to get all the customer keys, we could use the SCAN command and match on the wildcard customer:* to fetch all the keys. This would also return the count key which is not what we want. So maybe a better key for the count would be customer-all:count.
Import Customers
Let’s start creating some data. Generally we will often import the data from another source like csv or another database. Redis does not have its own import utility so it is up to us to write our own.
For this series of blogs I am going to use Python 3 and the Redis python library found here on github. Development is done on Visual Studio 2017 using the Python for Windows addin. I am going to use data from the infamous Northwind database to demonstrate how some relational data can be represented in Redis.
Each customer record is made up of the following fields. ID, Company, Contact, ContactTitle, Address, City, Region, PostalCode, Country, Phone, Fax. ID is the primary key.
There are a number of ways to represent this data in Redis:
- We could create a string key called customer:ALFKI and store the entire record as JSON. E,G. {“ID”:”ALFKI”,”Company”:”Alfreds Futterkiste”,”Contact”:”Maria Anders”,”ContactTitle”:”Sales Representative”,”Address”:”Obere Str. 57″,”City”:”Berlin”,”Region”:”NULL”,”PostalCode”:”12209″, “Country”:”Germany”,”Phone”:”030-0074321″,”Fax”:”030-0076545″}.
The problem with this approach is that when you need this customer, you are forced to bring entire record over to the client whether you want all the fields or not. - We could create one key per ID per field. Customer:ALFKI:company, Customer:ALFKI:contact, etc. This gets very tedious and will introduce lots of additional lists and sets for other access requirements.
- When storing multiple fields for a single key, the best approach is using a Hash.
Look at the 01_Import_Customers.py
script. We are using hmset to store each customer with a key of customer:. In addition we keep track of the number of customers in key customer-all:count using the incr command. This is not the most efficient way of inserting customers however; we only have 91 so it’s easy for demonstration purposes. On the Redis website is a document called Redis Mass Insertion that details how to insert millions of key values.
import settings
import redis
import csv
import sys
import os
def ProcessCSVFile(r, csvin):
with open(csvin, 'rt', encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quoting=csv.QUOTE_NONE, )
# Ignore Row Header
next(spamreader)
for row in spamreader:
ProcessCustomerRow(r, row)
def ProcessCustomerRow(r, row):
# CSV Header
# ID,Company,Contact,ContactTitle,Address,City,Region,PostalCode,Country,Phone,Fax
hkey = "customer:" + row[0]
# Delete old Customer:id key
r.delete(hkey)
rowdata = {}
rowdata["ID"] = row[0]
rowdata["Company"] = row[1]
rowdata["Contact"] = row[2]
rowdata["ContactTitle"] = row[3]
rowdata["Address"] = row[4]
rowdata["City"] = row[5]
if row[6] != "NULL":
rowdata["Region"] = row[6]
if row[7] != "NULL":
rowdata["PostalCode"] = row[7]
rowdata["Country"] = row[8]
rowdata["Phone"] = row[9]
if row[10] != "NULL":
rowdata["Fax"] = row[10]
r.hmset(hkey, rowdata)
r.incr("customer-all:count")
if __name__ == "__main__":
print("Importing Customers...")
_csvPath = os.path.dirname(os.path.dirname(__file__))
_customersCSV = os.path.join(_csvPath, "CSVs", "customers.csv")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Initialise our customer count to zero
r.set("customer-all:count",0)
# Insert Customers
ProcessCSVFile(r, _customersCSV)
print("Importing Customers Completed")
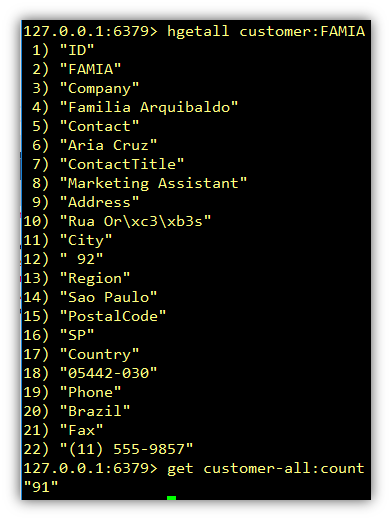
From the redis-cli prompt we can fetch all the keys and values for one hash key customer:FAMIA. Also getting the customer-all:count key returns 91 which is the number of customers inserted. I’ll explain more about the character conversion issue on line 10 later on.
Querying Customers
So now we have our customers let’s query them all. The idea is that you say, give me all keys that start with customer: and then for each key returned, fetch all the values for each field. We can use any one of the following commands:
- HVALS. Return all the values for one customer however; you need to know what field 0 is, field 1, etc.
- HGETALL. Returns a dictionary of every field and we can reference by field name.
- HMGET. This is the preferred command. It returns a list of the fields we specify zero indexed.
Look at the 02_Query_Customers.py script.
import settings
import redis
def ProcessCustomer(key):
# Get all keys and values from hash
_cust = r.hmget(key, "ID", "Company", "Contact", "City", "Country")
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8'),
_cust[3].decode('utf-8'),
_cust[4].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Customers...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Get all the Customer Keys. This does a SCAN under the covers
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format("ID","Company","Contact","City","Country"))
for key in r.scan_iter("customer:*"):
ProcessCustomer(key)
print("Querying Customers Completed")
Here is the output.
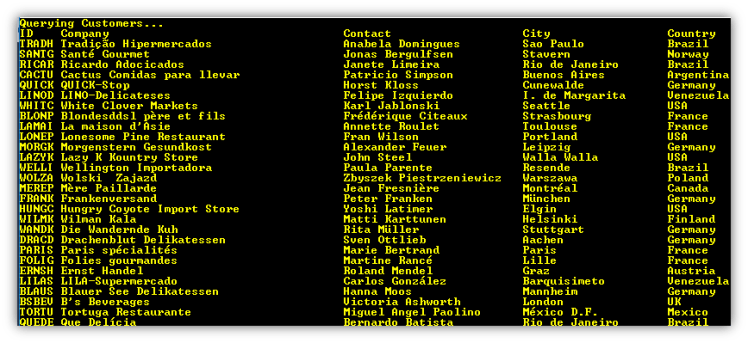
I mentioned above about character conversion issues. Redis stores data as bytes in UTF-8 format. The Redis commands do not do full character conversions, they just output the raw bytes and we just get the basic ASCII. Look at the output below.

When translated it should read

This is achieved by using the Python string decode function. _cust[0].decode(‘utf-8’)
This will only work correctly if the input CSV file is UTF-8 encoded and as long as you pass the value in correctly we can do the character conversion on the client.
When I opened the file I set the encoding to UTF-8. open(csvin, ‘rt’, encoding=’utf-8′).
Sorting Customers by Key Field
One thing you might want to do is output the data sorted by the ID. You may know there is a command called SORT and think that will help us however; SORT works on lists, sets and sorted sets. Not hashes.
We can achieve this by using a List, Set or Sorted Set to hold each customer ID. When we add a new customer, we add the ID to this key. When we delete a customer we delete the ID from this key.
Look at the 03_Create_Customers_Sort_Key.py script.
import settings
import redis
import csv
import sys
import os
def ProcessCSVFile(r, _sortkey, csvin):
with open(csvin, 'rt', encoding='utf-8') as csvfile:
spamreader = csv.reader(csvfile, delimiter=',', quoting=csv.QUOTE_NONE, )
# Ignore Row Header
next(spamreader)
for row in spamreader:
ProcessCustomerRow(r, _sortkey, row)
def ProcessCustomerRow(r, sortkey, row):
# CSV Header
# ID,Company,Contact,ContactTitle,Address,City,Region,PostalCode,Country,Phone,Fax
rowdata = {}
_id = row[0]
r.lpush(_sortkey, _id)
if __name__ == "__main__":
print("Reading Customers...")
_csvPath = os.path.dirname(os.path.dirname(__file__))
_customersCSV = os.path.join(_csvPath, "CSVs", "customers.csv")
_sortkey = "customer-id:sort"
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Delete the key in case we need to rerun
r.delete(_sortkey)
ProcessCSVFile(r, _sortkey, _customersCSV)
print("Reading Customers Completed")
This code creates a single key called customer-id:sort. Now we can use the SORT command to return a list of keys sorted alphabetically.
Look at the 04_Query_Customers_Sorted_By_ID.py script.
import settings
import redis
def ProcessCustomer(key):
hkey = "customer:" + key
# Get all keys and values from hash
_cust = r.hmget(hkey, "ID", "Company", "Contact", "City", "Country")
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8'),
_cust[3].decode('utf-8'),
_cust[4].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Customers...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Get all the Customer Keys. This does a SCAN under the covers
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format("ID","Company","Contact","City","Country"))
for key in r.sort("customer-id:sort", alpha=True):
ProcessCustomer(key.decode('utf-8'))
print("Querying Customers Completed")
Here is the output.
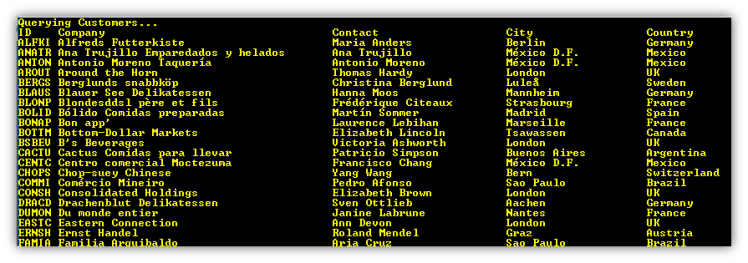
Notice the data is sorted by ID.
Sorting Customers by a Non Key Field
If we want to sort by a key other than the primary key, it is actually really simple. We still use our customer-id:sort list and just expand our SORT command with the BY argument.
Look at the 05_Query_Customers_Sorted_By_Country.py script.
import settings
import redis
def ProcessCustomer(key):
hkey = "customer:" + key
# Get all keys and values from hash
_cust = r.hmget(hkey, "ID", "Company", "Contact", "City", "Country")
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format(
_cust[0].decode('utf-8'),
_cust[1].decode('utf-8'),
_cust[2].decode('utf-8'),
_cust[3].decode('utf-8'),
_cust[4].decode('utf-8')
))
if __name__ == "__main__":
print("Querying Customers...")
# Connect to Redis
r = redis.Redis(host=settings.redisSettings["host"], port=settings.redisSettings["port"], password=settings.redisSettings["password"], db=settings.redisSettings["database"])
# Get all the Customer Keys. This does a SCAN under the covers
print("{:5s} {:40s} {:25s} {:20s} {:20s}".format("ID","Company","Contact","City","Country"))
for key in r.sort("customer-id:sort", by="customer:*->Country", alpha=True):
ProcessCustomer(key.decode('utf-8'))
print("Querying Customers Completed")
Here is the output.
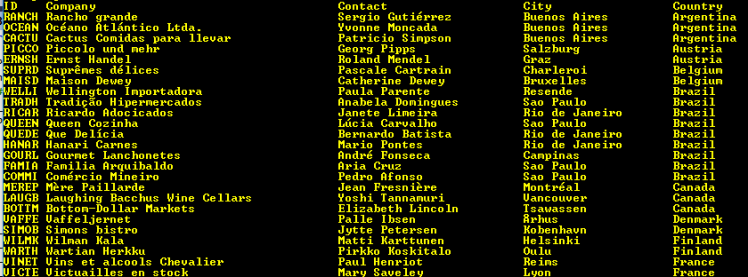
Notice the data is sorted by Country. You probably look at this and think that we need a composite sort key on Country and City. At the time of writing the SORT command does not except multiple BY arguments.
In the next blog I will look at handling NULL data and denormalization.
